내가 생각하는 딥러닝 모델링 과정에서 가장 중요한 작업이다. 오늘은 최적화에 대해서 알아보려고 한다.
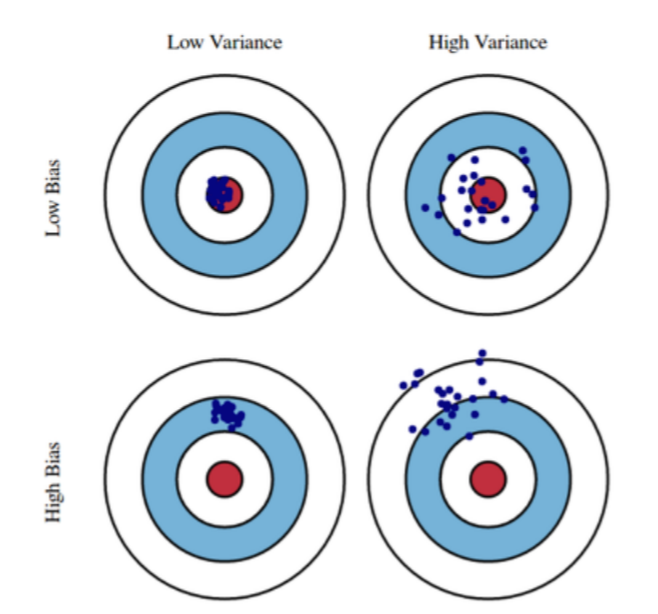
Generalization
train_set을 잘 학습시켰다고 해서 test_set이 잘 학습된다고 할 수 없다. 이 두개의 set 차이를 generalization gap 이라고 한다
Underfitting & Overfitting
test_set에 대해서 너무 잘 예측된다면, 그 set에서만 좋을 가능성도 높다. 이런 경우를 overfitting, 반대의 경우를 underfitting이라고 한다.
Cross-validation
test_set을 쓰기전, 결과를 미리 판단하기위해 train_set에서 subset으로 나눠 한 set을 validation으로 두고 판단한다. 이 때, 데이터의 수가 제한적이라면 k-fold 방법을 대개 사용한다.
k-fold : train_set을 n개의(지정가능) subset으로 나눠서 하나의 subset을 validation_set으로 두고 나머지를 train_set으로 둔다. 이 때 input을 train_set만을 이용, test 할때 validation_set을 이용한다.