CNN에서 C는 convolution, NN은 뉴럴 네트워크를 뜻한다. 여기서 convolution을 잘 모르는 분들이 있을 것 같다. 원래의 convolution은 디지털 신호를 처리할때 주로 이용하는 방법이다. 하지만, CNN에서의 convolution은 Input(이미지와 같은)값에서 feature을 뽑아내기 위한 용도로 사용된다.
만약 input이 이미지로 들어온다면? filter를 convolution하여 output(원래 이미지와 다른 형태의 이미지, 예를 들어 원래의 이미지에서 아웃라인만 잡는다거나..)을 출력시킬수 있다.
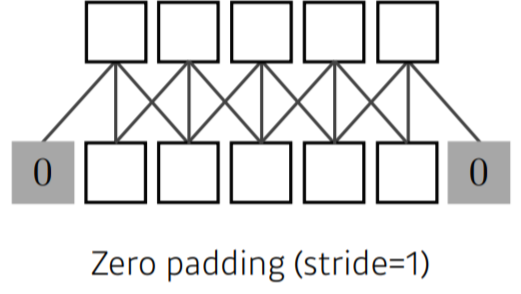
Stride & Padding
Stride
좌측은 input layer을 한칸씩 옮겨가며 연결, 우측은 2칸씩 옮겨가며 연결
Padding
input 양끝에 0을 추가해주면 (zero padding) input과 output의 채널을 동일하게 만들수 있다.
어떠한 모델의 파라미터를 계산하는 것은 중요하다. 파라미터의 수가 모델에 성능을 결정하는 결정적 역할을 하기 때문이다. 그래서 예제를 통해 계산법을 확실하게 알아두고 가려한다.
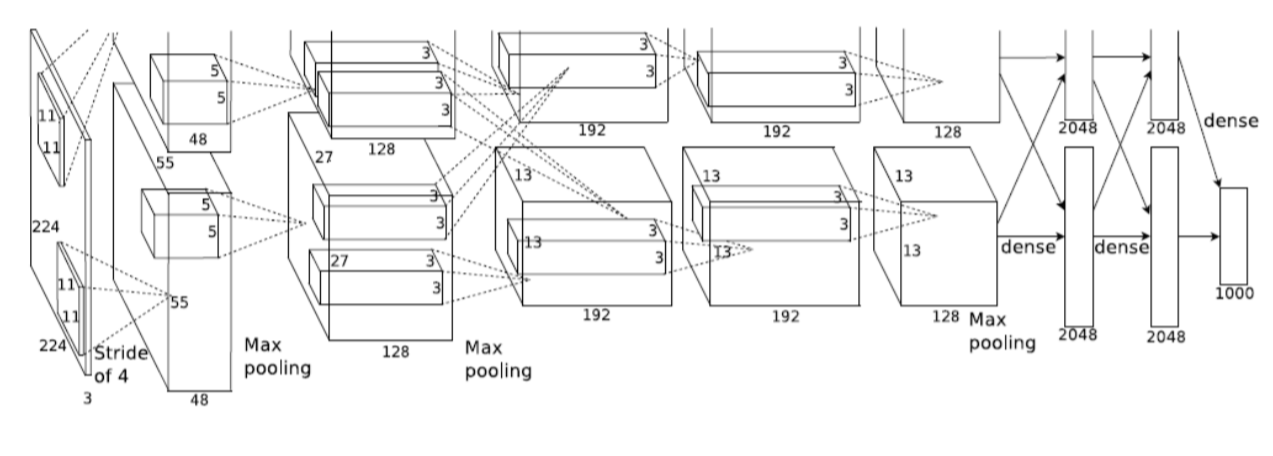
가장 먼저 알아둬야되는 개념은 행과 열 그리고 채널이다. 첫번째 그림을 보면 filter가 11*11*3 으로 이루어져있는걸 볼 수있다. 11by11은 행열의 행과열이고, 3은 채널의 크기이다.
첫번째 그림에서 두번째 그림으로 넘어갈 때 파라미터의 수를 계산해보면, 11*11*3*48*2 => 11*11*3이 나타내는 것은 첫번째 그림에서 filter의 크기를 나타낸다. => 48이 나타내는 것은 두번째 그림에서 채널의 크기이다 => 2가 나타내는 것은 두번째 그림에서 네트워크의 수이다. >>> 네트워크가 2개로 나누어져있는 것을 볼수있다. => 계산하면 약, 35000개의 파라미터가 나온다.
마찬가지로 3번째 그림의 파라미터, 4번째 그림의 파라미터, 5번째 그림의 파라미터, 6번째 그림의 파라미터를 구해보면, 각각 30만7천개, 88만4천개, 66만3천개, 44만2천개의 파라미터 개수가 구해진다.
6번째그림에서 7번째 그림으로 넘어갈 때, layer의 형태가 바뀌는 것을 볼 수 있다. Dense layer로 바뀌게 되는데, 즉 1차원 배열으로 표현된다.
계산법은 다음과 같다. >>> (13*13*128*2) * (2048*2) => 약 1억7천만개 이상의 파라미터가 존재하게 된다.
이후의 Dense layer들의 파라미터 수는 convolution layer보다 훨씬 높은 파라미터의 수를 가지게 되는 것을 볼 수 있다.
Modern CNN
AlexNet (위의 예제와 동일한 모델)
입력을 받은 후 네트워크가 2개로 나뉘어져 있다. GPU의 한계로 2개로 나누어서 계산이 필요했다.
5개의 convolution layer와 3개의 dense layer로 구성되어있다.
활성함수로 ReLU를 사용하였고 여러 정규화 기법을 사용하였다.
2012년 당시에는 이런 기법들이 사용되는 것은 당연하지 않았다.
VGGNet
3*3 convolution filter만을 사용한다.
그 이유는 3*3을 2번 사용한 필터가 5*5를 1번 사용한 필터보다 적은 파라미터 수를 가지기 때문이다.
GoogleNet
22개의 layer로 이루어져 있고, 비슷한 네트워크 구조가 반복된다.
google net의 가장 큰 특징은 inception block이 존재한다는 점이다.
Inception block : 원래의 convolution filter를 거치기 전에 1 By 1 filter를 먼저 수행하는 것이다. 이것은 파라미터 수를 크게 줄일 수 있는데, 그 이유는
다음과 같이 3 By 3 convolution filter 만을 적용 했을때는 좌측식과 값이 나온다.하지만, 1 By 1 convolution filter을 추가로 적용시키면 우측식과 같이 파라미터의 수가 줄어듬을 볼 수 있다. ** 단, 네트워크가 하나 추가되었다
ResNet
ResNet이 나오게 된 이유는, 파라미터 수가 많을 때 다음 2가지의 오류가 생긴다.
overfitting
train error와 test error가 비슷하게 감소하지만, train error보다 test error가 더 큰 상황, 즉 학습이 제대로 안되는 상황이다
여기서 2번을 해결하기 위해 identity map을 추가한다 >> 네트워크를 더 깊게 쌓아도 학습이 잘되게 된다.
bottleneck 구조를 가진다 >> n By n convolutio을 하기전에 1 By 1 conv를 통해 채널을 줄이고, 원래의 convolution하여 아웃풋채널을 맞춰주는 구조 (구글넷의 inception black 과 같은 방법)
DenseNet
concatenation
문제점 : 채널이 기하급수적으로 커짐(파라미터도 같이 커지게됨)
해결법 : transition block을 이용하여 줄여줌(1 By 1 convolution) 다시 dense block으로 늘리다가 다시 줄이고 반복