[Day 9] RNN & Transformer
2021. 8. 12. 22:22ㆍAI 부스트캠프
RNN
- Sequential model : dataset이 sequential하게 주어졌다면 우리는 RNN을 통해서 모델을 구축할 수 있을 것이다.
- Sequential이란? 일상생활에서 다루는 대부분의 정보들 ; 음성, 동작 등
- sequential 데이터에서 우리가 결국 얻고 싶은건 하나의 라벨(정보)이다. 예를들어, 음성데이터가 주어진다고 하면 그 음성데이터의 길이가 길어, 언제끝나는지 알 수 없다. 때문에 CNN을 사용하지 못한다
- CNN을 사용하지 못하는 이유는 몇개의 input값이 주어질지 모르기 때문
- 가장 기본적인 sequential model은 이전 데이터를 이용해 다음 데이터를 예측하는 것이다.
- sequential한 데이터를 해결하는 2가지 방법
- Markov model : 현재는 과거에만 종속된다(과거의 일부의 데이터만 고려한다.
joint probablity로 표현하기 쉬워진다. - latent autoregressive model : hidden layer에 과거정보를 축약해서 저장한다
- Markov model : 현재는 과거에만 종속된다(과거의 일부의 데이터만 고려한다.
- RNN
- 시간순으로 모델링이 가능하지만 복잡하고, 파라미터를 공유하게된다. 즉, input이 커지게 되어 과거에 있던 정보가 미래까지 살아남기 힘들다.
- 따라서 우리는 중요한 정보들을 가지고 있다가 써야 되는데, 이때 long-term한 방법을 이용해야 된다.
- 활성화 함수를 만약 sigmoid or tanh 를 쓰게 되면, 정보가 중간에 죽어버리게 된다.
- 활성화 함수를 ReLU를 쓴다면, 계속 중첩되어 학습할 때 네트워크가 터질 수 있다.
다음과 같이 계속 중첩이 된다.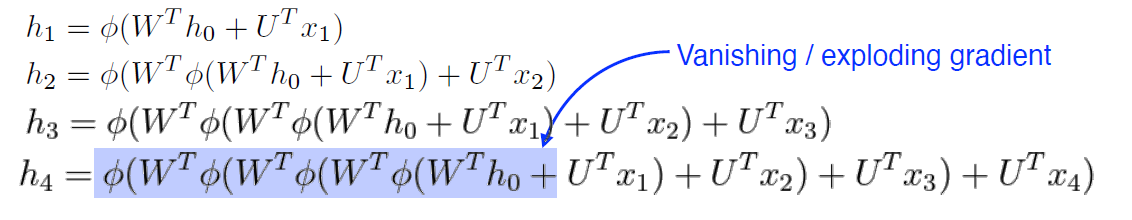
- 따라서 LSTM을 사용한다.
- LSTM
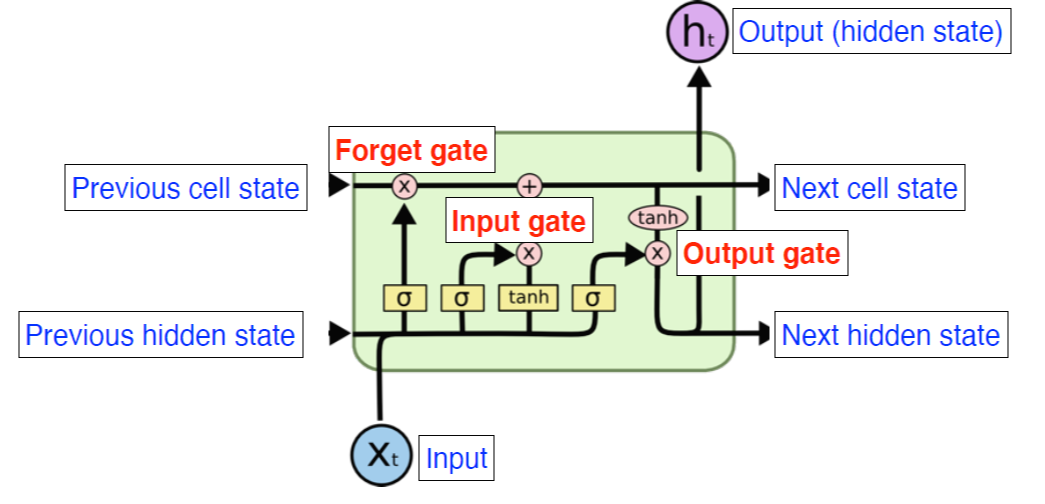
- 위의 그림은 LSTM의 기본 구조이다.
- 쉽게 생각하면 컨베이너벨트라고 생각하면 된다. 물건이 벨트위로 올라오면 정보들의 유용함의 정도에 따라 분류하여 내보내는 것이다.
- LSTM의 구조에서 가장 중요한 sigmoid 3개에 대해 알아보자
- forget gate : 어떤 정보를 버릴지
- input gate : 어떤 정보를 위로 올릴지
- output gate : 다음 layer에 어떤 것을 버리고 어떤 정보를 추가할지
- dense layer 방식으로 구성되므로 파라미터가 엄청 커진다
- GRU 방법을 사용한다 : 적은 파라미터로 좋은 성과를 낼 수 있다.
- 하지만 요즘 transformer이 나오면서 RNN이 점차 바뀌고 있다.
TransFormer
※ 이 개념자체는 매우 어렵고 공부하면서도 햇갈리는 부분이 많았다. 최대한 풀어서 설명해보려 한다.
- Moto : RNN의 한계를 극복한다 ; Sequential data에서는 중간 데이터가 빠지거나, 순사가 바뀌면 학습이 힘들다.
- def. Attention이라는 구조를 활용한 모델 / ex) 어떤 sequential한 문장이 주어지면 다른 문장으로 바뀌는 것 ; 번역
- 2가지 원리를 이해해보자!
- n개의 단어가 어떻게 인코더에서 한번에 처리되는지
Q vector와 K vector을 내적해야 되므로 차원이 같아야 된다!!Transformer은 데이터 전체를 한번에 돌리므로, Cost가 1000^2 이 나온다.더 유연하고 많을 것을 표현 가능하다는 장점이 있다.
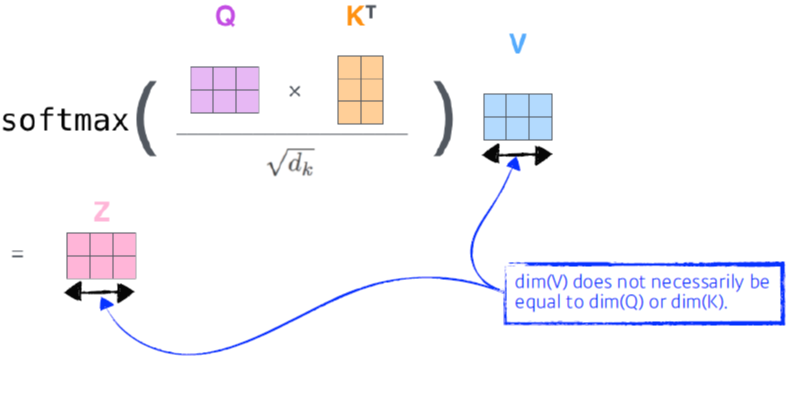
- n개의 단어가 들어간다
- self-attention : 단어가 주어지면 벡터를 내보낸다. 만약 3개의 단어가 주어지면, 첫번째 단어를 내보낼때 나머지 단어들과의 연관을 고려해서 벡터화 한다.
- input단어가 주어지면, 3가지 형태의 벡터를 만든다.(만들때 MLP 이용)
- Querie, Key, Value
- cf. psitional incording이 필요하다 > 순서가 필요하기 때문!
- 따라서 처리의 한계와 메모리의 한계가 존재하는 단점과
- RNN은 데이터 하나마다 계산 되므로 input이 1000개면 1000번 돌리면 학습된다
- ex) thinking chair , 2개의 단어가 input으로 주어진다면?
- score vector을 계산한다thinking과 나머지 단어의 연관성을 구할 수 있다
- thinking의 Q vector와 나머지단어(여기서는 chair)의 K vector을 내적한다
- n개의 단어가 어떻게 인코더에서 한번에 처리되는지
- 인코더와 디코더 사이에 어떤 정보를 주고받는지
- 디코더는 인코더의 정보들을 가지고 생성하게 되는데 , Key와 Value를 보내게 된다.
- 디코더와 인코더의 관계 : 이전까지 디코더에 들어간 단어들로만 Queriy를 만들고, Key, Value는 인코더에서 주어지는 벡터로 사용한다.
'AI 부스트캠프' 카테고리의 다른 글
| [Week 3] Pytorch(통합정리) (0) | 2021.08.20 |
|---|---|
| [Day 10] GAN (0) | 2021.08.13 |
| [Day 8] CNN (0) | 2021.08.11 |
| [Day 7] Optimization (0) | 2021.08.10 |
| [Day 6] 딥러닝 basic & MLP (0) | 2021.08.09 |