[Week 3] Pytorch(통합정리)
2021. 8. 20. 22:29ㆍAI 부스트캠프
Pytorch의 문법, 함수, 클래스 등 너무 방대한 양을 담고 있기에 이 글하나에 전부 적기 힘들다. 만약 더 공부를 원하면,
https://tutorials.pytorch.kr/ : 파이토치 공식사이트를 이용해서 방대한 문서들을 참고하고, 파이토치 시작하기 섹션은 꼭 한번 따라하는 것을 추천한다.
특히 이번글에서 다룰 것은 모델링하는 것이 아닌, Dataset과 Dataloader을 통해 데이터입력을 받고, 쓰는 방법을 익히려고 한다.
>> 모델링은 구글링만 해도 많은 자료들이 있기에 클론 코딩이나, 문서를 통해 배우기 수월하다.
Pytorch의 기본 특징
1. Dynamic Computation Graph : 연산의 과정을 그래프로 표현
2. Difine by Run : 실행을 하면서 그래프를 생성하는 방식
* Tensorflow 경우에는 그래프를 먼저정의하고 실행시점에 데이터를 나르는 방식
3. Numpy 구조를 가지는 Tensor 객체로 Array 표현
4. 지동미분을 지원하여 DL 연산 가능
Tensor
- 다차원 배열을 표현하는 pytorch 클래스(= ndarray)
- numpy 배열과의 다른점 : tensor는 GPU에 올려서 사용 가능하다
- handling
- view : tensor의 shape을 변환
- squeeze : 차원의 개수가 1인 차원을 삭제
- unsqueeze : 차천의 개수가 1인 차원을 추가
- operation
- 행렬곱셈 연산은 mm을 이용한다
- 나머진 numpy와 동일
AutoGrad
##자동미분의 지원 >>>> backward() 사용
w = torch.tensor(2.0, requires_grad=True)
y = w**2 ## y = w^2
z = 10*y + 2 ## z = 10y + 25
z.backward() ## z = 10w^2 + 25
w.grad
Dataset
사실 dataset은 그림하나로 요약이 가능하다
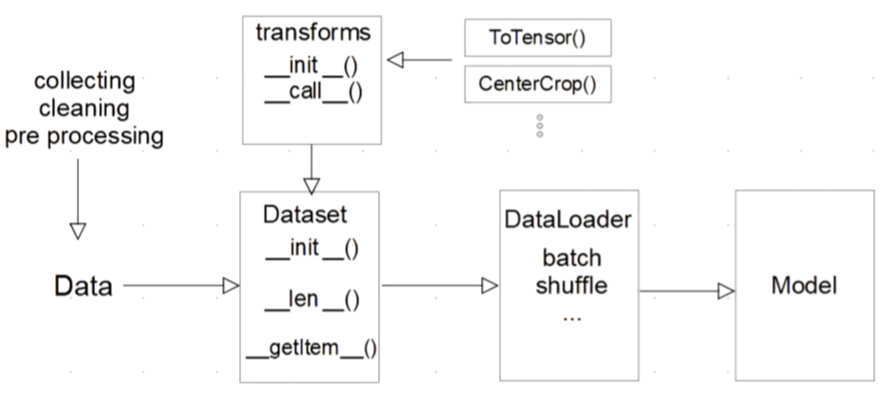
한 번 쭉보면서 넘기고, 차근차근 알아보자
- 데이터 입력을 정의하는 class
- 데이터 입력방식의 표준
- input 데이터의 종류마다 다른 입력을 정의한다
import torch
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, input, label):
self.X = input
self.y = label
def __len__(self):
return len(self.y)
def __getitem__(self, idx):
label = self.y[idx]
input = self.X[idx]
return input, label__init__ : 초기데이터 생성 방법지정
__len__ : 데이터의 전체길이
__getitem__ : index값에 따른 데이터를 반환하는 형태 지정
* 이것을 굳이 왜 사용하나? >> 데이터 셋에 대한 표준화된 처리방법 제공이 필요하다 >> 후속 연구자나 팀적으로 큰 도움이 된다
DataLoader
이 부분은 코드를 보면서 이해하는 것이 좋을 것 같다.
text = ['Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels)
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))
# {'Text': ['Glum', 'Sad'], 'Class': ['Negative', 'Negative']}
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
for dataset in MyDataLoader:
print(dataset)
>>> {'Text': ['Glum', 'Unhapy'], 'Class': ['Negative', 'Negative']}
>>> {'Text': ['Sad', 'Amazing'], 'Class': ['Negative', 'Positive']}
>>> {'Text': ['Happy'], 'Class': ['Positive']}
다음과 같이 dataloader은 내가 지정해준 파라미터에 따라서 dataset으로 부터 데이터들을 가공시킨다
모델 불러오기
- model.save()
- 학습의 결과를 저장하기 위한 함수
- model architecture와 parameter 저장
- 학습 중간 과정의 저장을 통해 최선의 결과모델을 선택
- checkpoint
- 학습의 중간결과를 저장하여 최선의 결과를 선택
- 일반적으로 epoch, loss, metric을 함께 저장
- colab에서의 지속적인 학습을 위해 필요 (colab은 8시간마다 초기화됨)
-
torch.save({ 'epoch': e, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': epoch_loss, }
Monitoring tool
긴 학습시간 >>> 기다림의 기록이 필요하다
Tensorboard 와 weight&biases 를 사용가능
- Tensorbooard
- TensorFlow의 프로젝트로 만들어진 시각화 도구
- 학습 그래프, 학습결과의 시각화 지원
- Pytorch도 연결가능하다
- 정확도, loss 등 상수값의 epoch을 표시, weight값의 분포를 표현, image표현(예측 값과 실제 값을 비교)
-
import os logs_base_dir = "logs" os.makedirs(logs_base_dir, exist_ok=True) -
from torch.utils.tensorboard import SummaryWriter import numpy as np exp = f"{logs_base_dir}/ex3" writer = SummaryWriter(exp) for n_iter in range(100): writer.add_scalar('Loss/train', np.random.random(), n_iter) writer.add_scalar('Loss/test', np.random.random(), n_iter) writer.add_scalar('Accuracy/train', np.random.random(), n_iter) writer.add_scalar('Accuracy/test', np.random.random(), n_iter) writer.flush() -
%load_ext tensorboard %tensorboard --logdir "logs" >>> 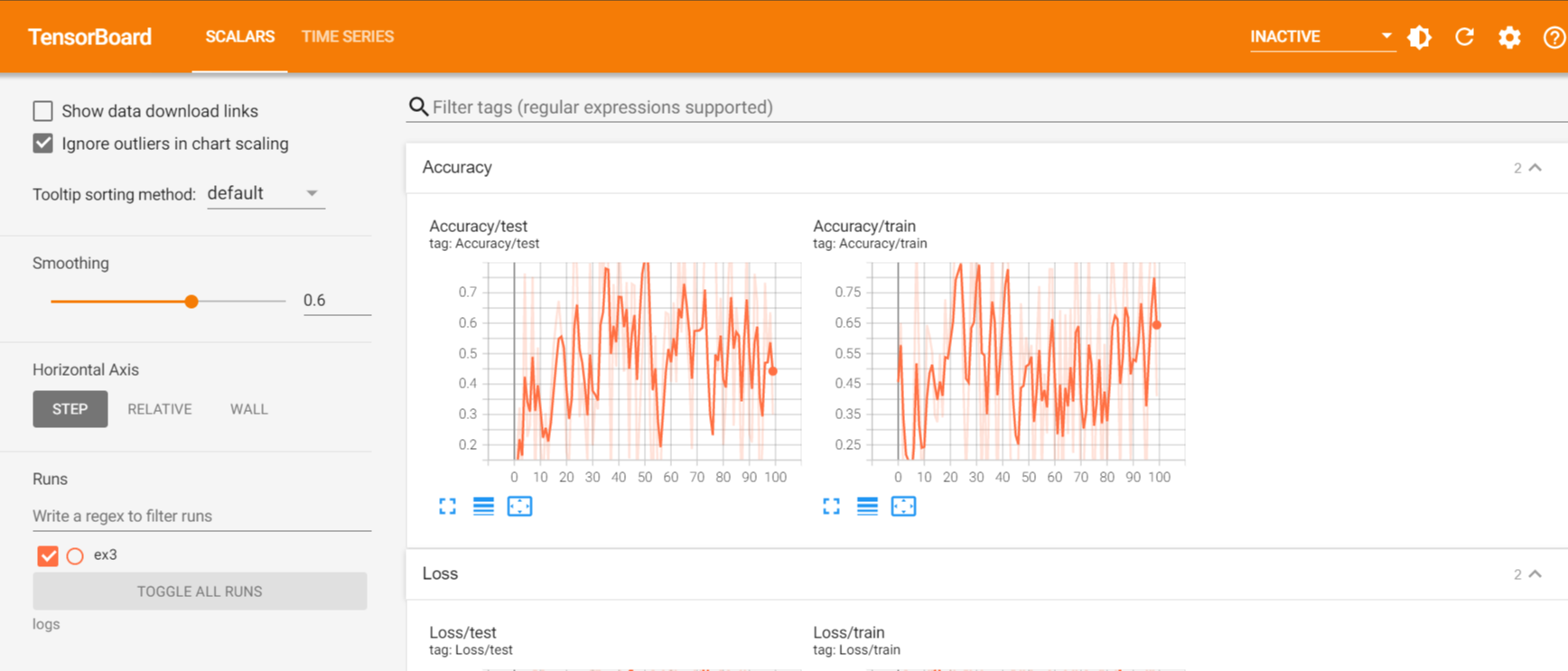
다음과 같이 출력되는 것을 볼 수 있다.
- weight & biases
- 협업(git처럼)을 제공한다
- 사이트에서 다른 사람들과 그래프(시각화) 공유가 가능하다
- 단, 유료이므로 주의
'AI 부스트캠프' 카테고리의 다른 글
| [Week5 / Day 2] Annotation Data Efficient Learning[ (0) | 2021.09.09 |
|---|---|
| [Week 5/ Day 1] Image Classification (0) | 2021.09.07 |
| [Day 10] GAN (0) | 2021.08.13 |
| [Day 9] RNN & Transformer (0) | 2021.08.12 |
| [Day 8] CNN (0) | 2021.08.11 |