[Week5 / Day 2] Annotation Data Efficient Learning[
2021. 9. 9. 22:40ㆍAI 부스트캠프
Data augmentation
def. 데이터를 패턴을 통해 분석할때, 편식하지 않고 골고루 학습을 시켜야되는데 실제로는 많은 bias가 존재한다.
우리가 실제로 취득하는 데이터 셋은 밀도가 높지않고, bias가 존재한다. 이것을 매꿀 수있는 방법이 augmentation이다.
즉 데이터의 밀도를 높여준다고 생각하면 된다.
- Image data augmentation
- OpenCV 와 Numpy가 data augmentation을 이용하는데 많은 방법들을 제공한다
- Goal : training dataset을 실제 데이터와 비슷하게 만드는 것
- data augmentation methods
- 밝기 조절 : Brightness (RGB값을 이용)
- Rotate, filp : 데이터를 뒤집거나 회전시킨다
- Crop : 랜덤 혹은 원하는 부분만을 추출
- Affine transformation
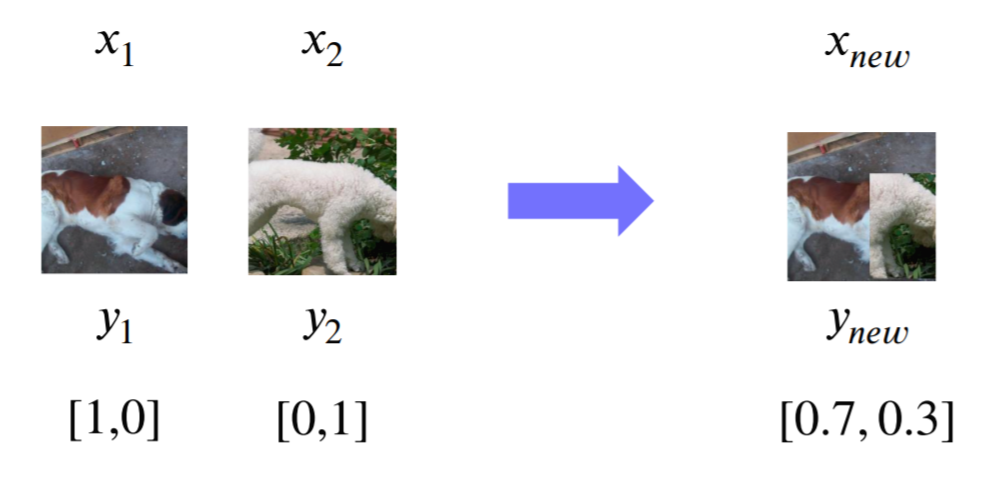
- CutMix : 서로 다른 부분을 붙여서 하나의 이미지로 만든다
Pre-Training
- transfer learning : 어떤 데이터 셋에서 배운 지식을 다른 데이터셋에서도 활용하는 것, 이것이 가능하게 하는 이유는 공통된 지식들이 의외로 많기 때문이다
- convolution layer은 freeze 한 후, fully connected layer을 학습됬던 데이터로 대체한다
- convolution layer은 freeze 한 후, fully connected layer을 학습됬던 데이터로 대체한다
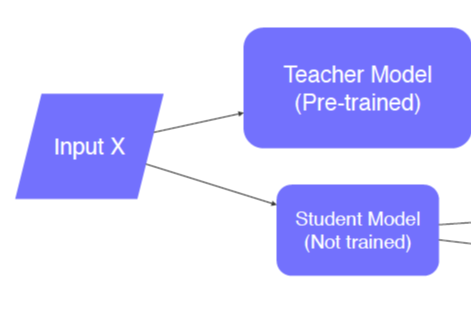
- knowledge distillation
- Teacher(Alread trained) + Student(not trained)
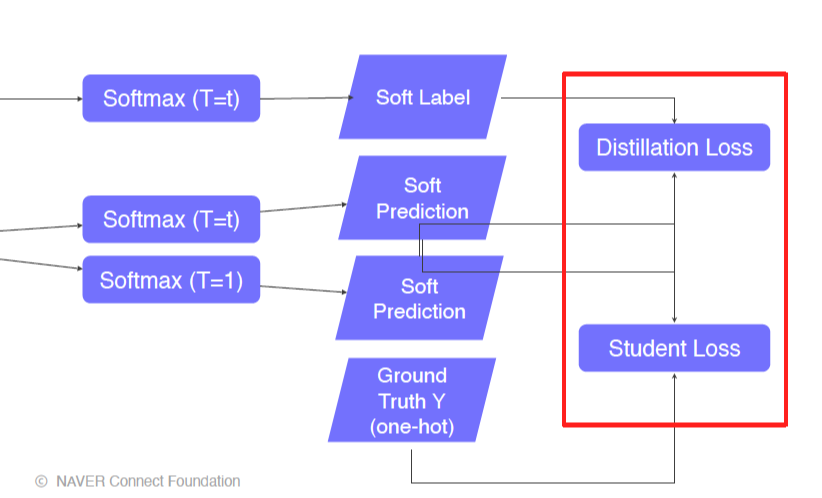
- student loss는 CrossEntropy loss로 student network와 true label사이의 loss이다.
- 이 두개의 loss의 weighted sum을 해나가는 과정이라고 할 수 있다.
Unlabeled dataset for training
- Semi-supervised learning
- Pseudo-labeling을 진행한다
- 미리 학습된 모델을 이용하여, unlabeled 된 data를 training 시킨다

- self-training
- def. Augmentation + Teacher/Student networks + semi-supervised learning
- 과정
- 라벨링된 데이터를 학습 시켜놓는다.
- unlabeled 된 것을 이 모델로 학습시킨다
- 합쳐서 student 모델을 만든다
- teacher 모델을 없애고 student 모델을 teacher 모델로 만든다
- 이 과정을 반복하게 되면 매 반복마다 스튜던트 모델은 점점 커진다
- 경량화를 통해 경제적인 부분을 해결한다.

'AI 부스트캠프' 카테고리의 다른 글
| [Week6 & Day 3] Conditional Generative Model (0) | 2021.09.16 |
|---|---|
| [Week6 & Day1] CNN Visualization (0) | 2021.09.14 |
| [Week 5/ Day 1] Image Classification (0) | 2021.09.07 |
| [Week 3] Pytorch(통합정리) (0) | 2021.08.20 |
| [Day 10] GAN (0) | 2021.08.13 |