[Day 1] numpy와 pandas
2021. 8. 6. 17:03ㆍAI 부스트캠프
- numpy(numerical python)
- 특징
- 일반 list에 비해 빠르고 효율적임
- 반복문을 쓰지 않고 data list를 처리가능
- c,c++와 통합가능
- 선형대수와 관련된 기능 제공
- np array의 특징
- 하나의 데이터 타입만 배열에 넣을 수 있다
- 다이나믹 타이핑이 지원되지 않는다
- C의 array를 사용하여 배열을 생성한다
-
test_arr = np.array([1, 2, 3], float) test_arr >>> array([ 1. , 2., 3.])
- np 배열의 종류
- 1차원(vector) : 위의 예제처럼 1차원 배열로 되있는 경우
- 2차원(matrix) : c의 2차원 배열로 생각하자
- reshape
- 배열모양의 크기를 변경한다. ex) matrix -> vector
- flatten
- 2차원이상의 배열을 1차원 배열로 변경한다.
- indexing / slicing
-
## indexing test[0][0] = 8 test[0,0] >> 8 ## slicing test2 = np.array([[1,2,3,4,5], [6,7,8,9,10]], int) test2[:, 2:3] >> array([[3,4], [8,9]]) ### 전체 행의 2~3번째 열을 추출
-
- zeros : 0으로 초기화된 배열 생성
- ones : 1으로 초기화된 배열 생성
- empty : 쓰레기값으로 초기화된 배열 생성
- identity : 단위행렬 생성
- eye : 대각선이 1으로 초기화된 배열 생성
- random : np.random.normal >> 정규분포 / np.random.uniform >> 균등분포
- mean, std : 각각 평균과 표준편차를 리턴
- concatenate
- vstack : 행을 연결
- hstack : 열을 연결
- concatenate : 내가 원하는 축을 기준으로 연결
- broadcasting
- 차원이 서로 다른 배열간의 연결을 해준다.
- comparisons
- 배열의 크기가 동일 할 때, 원소간의 비교결과를 boolean 타입으로 return 해준다
- 파이썬 6강의 numpy ppt의 예제들을 타이핑하면서 연습!
- 특징
- pandas
- 특징
- numpy 라이브러리와 통합하여 강력한 스프레드시트 처리기능 제공
- 데이터처리 및 통계 분석을 위해 사용
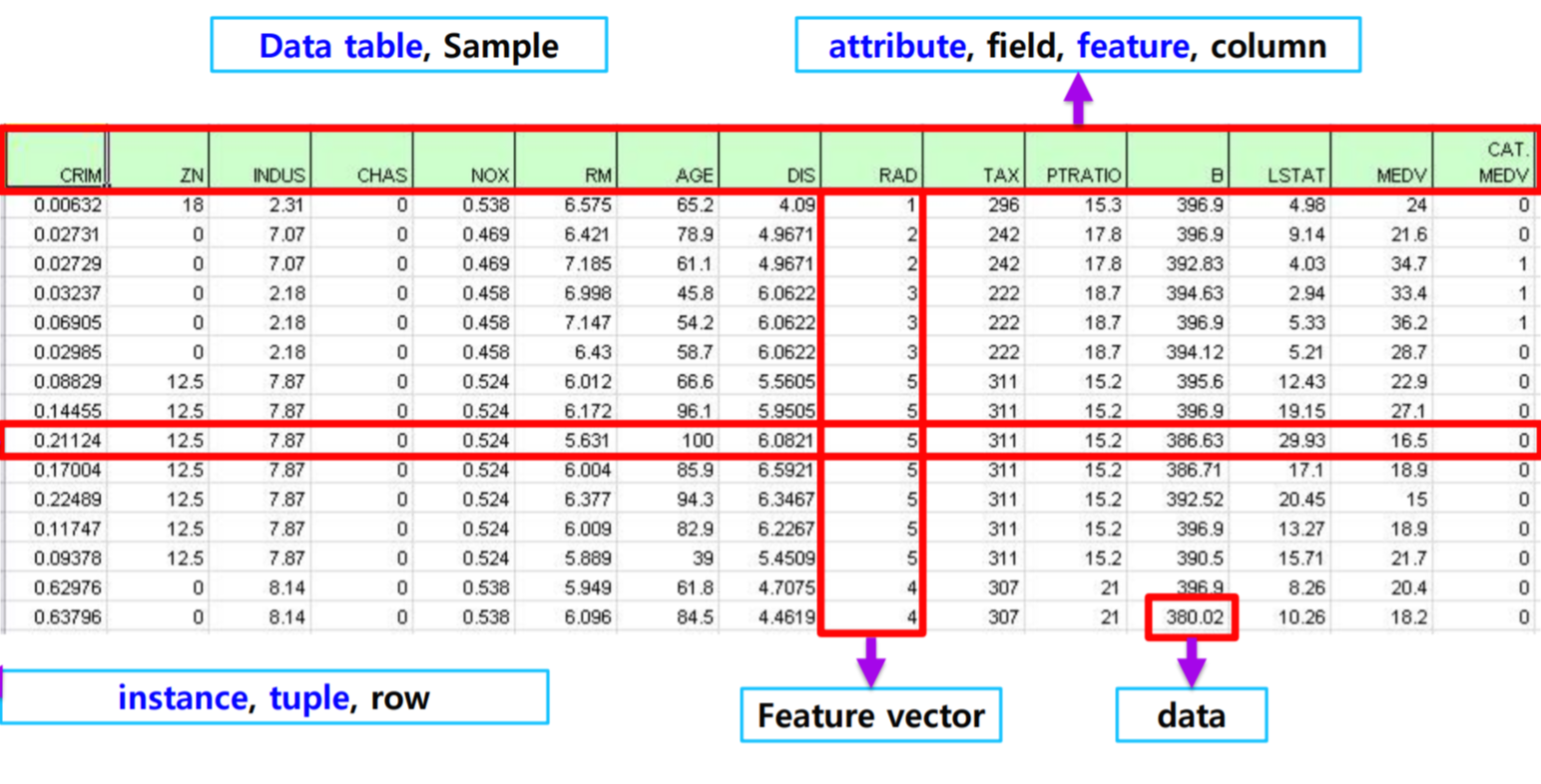
1. y(속성, 열) 2. x(특정열의 모든 행) 3.data(하나하나의 값들) - 데이터를 불러와서 dataframe을 생성할 수 있다.
- DataFrame indexing
-
df["x"].iloc[1:] >>> x라는 속성을 1번째 행부터 끝까지 출력함
-
- DataFrame drop
- drop :
df.drop([0,1,2,3]) >>> 0,1,2,3 행을 drop시킴 ######################## df.drop("x", axis = 3) >>> 속성값(y)들중 x속성의 전체 행을 drop시킴
- drop :
- 기타 여러 함수들이 존재하고 그 함수들만의 특징, 장점들이 많다. 하지만 그것을 다 정리하면서 외우는것은 비효율적이라고 생각된다. 어떤 함수들이 있는지 머리속에 넣어두는 것으로 만족하고 내가 필요한 상황이오면, 구글링이나 강의자료를 통해서 충분히 써먹을 수 있을 것 같다.
- 특징
'AI 부스트캠프' 카테고리의 다른 글
| [Day 7] Optimization (0) | 2021.08.10 |
|---|---|
| [Day 6] 딥러닝 basic & MLP (0) | 2021.08.09 |
| [Day 5] 확률/통계학 (0) | 2021.08.06 |
| [Day 4] 경사하강법 (0) | 2021.08.05 |
| [Day 3] 파이썬의 자료구조 (0) | 2021.08.04 |