[Day 5] 확률/통계학
2021. 8. 6. 14:06ㆍAI 부스트캠프
*** AI 엔지니어가 필수적으로 익혀야 하는 수학적 지식분야 : 선형대수 / 확률 / 통계 <<< 3가지는 완벽하게 이해하고 개념적으로 통달한 상태여야 한다!
- 딥러닝에서의 확률론
- loss function의 작동 원리는 통계학적인 해석이 필요하다.
- regression(예측오차의 분산)과 classification(모델 예측의 불확실성)의 분산및 불확실성을 최소화하기 위한 측정이 필요하다 >> 확률
- 이산형 확률변수 : 경우의 수를 서메이션(Σ)해서 모델링한다.
- 연속형 확률변수 : 범위내에 있는 데이터들을 적분하여 모델링한다.
- 조건부확률
- regression : 조건부 기대값 E를 추정한다.
- 기대값(expectation)이란 > 데이터를 대표하는 통계량, 기대값을 이용해 분산, covariance 등을 구할 수 있다.
- classification : softmax함수는 오메가와 가중치행렬을 통해 조건부 확률을 계산한다.
- 몬테카를로 샘플링 : 대부분의 기계학습 문제들은 데이터들이 어떤 확률분포를 가지는지 모른다. >> 그렇다면 기대값을 어떻게 구해야하나?? >> 몬테카를로 샘플링을 이용한다. (이산 and 연속 둘다 적용가능)
- independent한 추출만 보장된다면 수렴성을 보장한다.
- 편미분 , 연쇄법칙 복습하기!
- 딥러닝에서의 통계학
- 모수??
- 통계적 모델링 : 적절한 가정을 두고 확률분포를 추정하는 것
- 근사적인 확률분포 : 데이터의 개수가 유한하기 때문에 모집단의 정확한 분포를 알기 힘들다.
- 모수적 방법론 : 데이터가 어떤 분포를 따른다고 미리 가정한 후, 그 분포를 결정하는 모수를 추정하는 방법
- 비모수적 방법론 : 특정 분포를 가정하지 않고, 모수의 개수가 유연하게 바뀌는 것
- **주의 : 비모수는 모수가 없다는 뜻이 아니다!!
- 모수 추정하기
- 데이터의 확률분포를 가정완료
- 정규분포의 모수는 평균과 분산으로, 이를 추정하는 통계량이 존재한다.

표본평균 표본분산 - 이렇게 추정한 통계량의 확률분포를 표집분포(sampling distribution)이라고 한다. / N이 커질수록 정규분포를 따르게 되는데, 그 이유는 N 즉 데이터의 개수가 커지면 그래프가 중앙에 집중 되기 때문이다 >> 중심극한정리
- MLE(maximum likelihood estimation)
- 표본평균, 표본분산의 한계 : 확률분포마다 모수가 달라지게 되므로 적절한 통계량도 달라진다
- 이론적으로 가능성이 가장 높은 모수를 측정하는 방법 : MLE
- 데이터가 서로 independent하다면 로그MLE도 이용가능하다 >> log MLE를 이용하는 이유?? >> 시간효율성이 훨씬 좋기때문 ( O(n) >>> O(logn) )
- 정규분포에서의 MLE
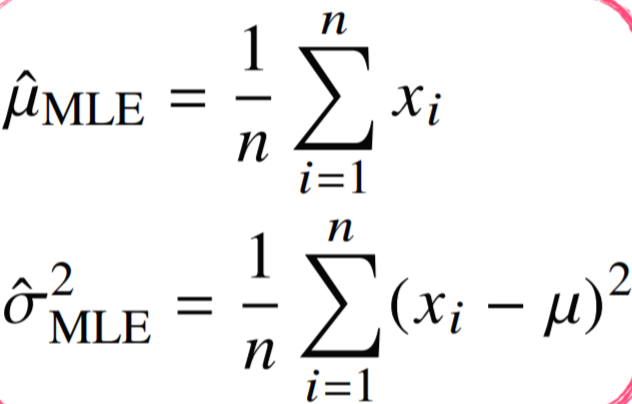
평균과 분산
- 베이즈 정리 : 조건부확률을 이용한 정보갱신 방법을 알려준다.

Bayes' theorem - P(D|seta) : D일때 seta일 확률
- 정확한 이해는 참고자료의 예제를 보면서 직접 계산해보자
- 모수??
'AI 부스트캠프' 카테고리의 다른 글
| [Day 6] 딥러닝 basic & MLP (0) | 2021.08.09 |
|---|---|
| [Day 1] numpy와 pandas (4) | 2021.08.06 |
| [Day 4] 경사하강법 (0) | 2021.08.05 |
| [Day 3] 파이썬의 자료구조 (0) | 2021.08.04 |
| [Day 2] 파이썬의 String (0) | 2021.08.03 |