2021. 10. 9. 15:38ㆍAI 부스트캠프
이번 Object Detection 컴페티션에서 내가 맡은 모델중 하나인 YOLOv5에 대해서 코드단까지 자세하게 설명하려 한다.
YOLOv5 def.

YOLOv5는 같은 One-stage detector인 EfficientDet보다 성능이 월등하게 좋아진 것을 볼 수 있다.
그럼 YOLOv5가 다른 YOLO version과 비교했을 때 갖는 장점은 무엇이 있을까?
>>> backbone + head
backbone : CSPNet(YOLOv4와 같음)
- CNN의 학습능력 강화 : 정확도를 유지하면서 경량화 가능
- 연산 Bottleneck 삭제 : v3 기준으로 bottleneck 80% 줄임
- 메모리의 cost 감소
Head : Anchor Box를 이용하여 Bounding Box를 생성한다
Preprocessing
1. Dataset 준비
YOLO를 이용하기전에 우리가 가장 먼저 해야되는 일은 무엇일까? 바로 데이터셋의 준비이다. 여러분들이 원하는 데이터셋(이번 대회의 Dataset은 Trash dataset임을 미리 밝힌다)을 준비하고 오는 것을 우선적으로 해야한다.
참고로, COCO dataset으로 준비해야 된다. (YOLO의 pretrained 모델은 COCO dataset으로 사전학습되었기 때문)
2. Data type 변환
YOLOv5를 이용하기 위해 COCO type의 데이터셋을 YOLO type으로 변환 시켜 주어야 한다.
COCO dataset의 bounding box : 좌측상단의 x,y 좌표 + w + h 로 구성

YOLO datset의 bounding box : box의 중심점의 x,y + 전체이미지의 상대적 w + h
즉, 이러한 이유때문에 형 변환작업이 필요하다.
데이터셋은 다음과 같이 이미지 파일과, 이 이미지들의 정보를 담은 json파일로 이루어져 있을 것이다.
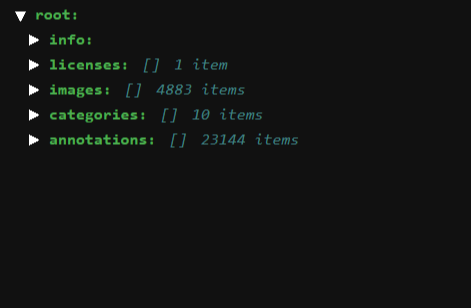
convert2yolo 라이브러리를 이용하여 손쉽게 바꿔줄 수 있다.
$ mkdir convert2Yolo
$ cd convert2Yolo
$ git init
$ git remote add origin https://github.com/ssaru/convert2Yolo.git
$ git pull origin master
$ pip3 install -r requirements.txt
convert2Yolo 폴더 안에 example.py파일을 통해 변환을 시켜줄 수 있다.
$ python3 example.py
--datasets COCO
--img_path /opt/ml/detection/dataset ##이미지 경로
--label /opt/ml/detection/dataset/valid_v3_f1.json ## 이미지의 정보를 담은 json파일 경로
--convert_output_path /opt/ml/detection/dataset ## 변환 txt를 저장할 경로
--img_type ".jpg" ## 이미지 파일의 타입
--manifest_path /opt/ml/detection/dataset ## darknet 프레임워크을 이용하여 학습할 경우에는 데이터셋의 이미지가 어디 있는지 이미지마다 파일 경로가 적혀있는 *.txt파일을 요구하게 됩니다. 해당 파라미터는 darknet 프레임워크를 위한 파라미터이지만, 불필요한 경우에 생략할 수 없으므로 무조건 적어주어야 합니다.
--cls_list_file /opt/ml/detection/dataset/name ## name이라는 txt 파일에 class name을 담아줘야 한다
name.txt 파일은 class의 이름들을 다음과 같은 format으로 작성해주면 된다.

변환 완료된 manifest.txt파일의 모습

Training
현재 위치의 디렉토리에 yolov5를 설치해보자
$ git clone https://github.com/ultralytics/yolov5.git
만들어진 yolov5로 들어가서 필요한 라이브러리들을 설치해주자
$ cd yolov5
$ pip install -r requirements.txt
자! 그럼 어느정도 준비는 끝났고, custom dataset을 학습시키기 위해서는 2가지가 우선적으로 필요하다.
- custom.yaml
-
train: /opt/ml/detection/dataset/manifest_train.txt val: /opt/ml/detection/dataset/manifest_val.txt #test: /opt/ml/detection/dataset/manifest_test.txt # number of classes nc: 10 # class names names: ["General trash", "Paper", "Paper pack", "Metal", "Glass", "Plastic", "Styrofoam", "Plastic bag", "Battery", "Clothing"] - 다음과 같은 형식으로 작성을 해주면 되고, 별 어려움은 없을 것이라고 생각한다
-
- parameter.yaml
-
lr0: 0.0117 lrf: 0.0855 momentum: 0.921 weight_decay: 0.00029 warmup_epochs: 1.2 warmup_momentum: 0.948 warmup_bias_lr: 0.147 box: 0.0407 cls: 0.71 cls_pw: 1.15 obj: 1.24 obj_pw: 1.19 iou_t: 0.2 anchor_t: 2.35 anchors: 2.14 fl_gamma: 0.0 hsv_h: 0.00924 hsv_s: 0.9 hsv_v: 0.657 degrees: 0.0 translate: 0.0594 scale: 0.0936 shear: 0.0 perspective: 0.0 flipud: 0.0 fliplr: 0.5 mosaic: 0.999 mixup: 0.0 copy_paste: 0.0 # segment copy-paste (probability) - 이것도 마찬가지로 하이퍼 파라미터들을 자신의 데이터셋에 맡게 조정하여 작성해 주면 된다.
-
이제 train.py 파일을 이용하여 학습을 시켜줄 것인데 모든 하이퍼 파라미터를 설명하기 보다는 중요한 것들, 해석하기 어려운 것들만 골라서 설명해보려고 한다.
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
'AI 부스트캠프' 카테고리의 다른 글
| [End...] 부스트캠프를 마치며... (8) | 2022.01.03 |
|---|---|
| [Detectron2] code level review (0) | 2021.09.28 |
| [Week6 & Day4] Image captioning (0) | 2021.09.17 |
| [Week6 & Day4] Multi-Modal Learning (0) | 2021.09.17 |
| [Week6 & Day 3] Conditional Generative Model (0) | 2021.09.16 |