[Week6 & Day4] Image captioning
2021. 9. 17. 15:03ㆍAI 부스트캠프
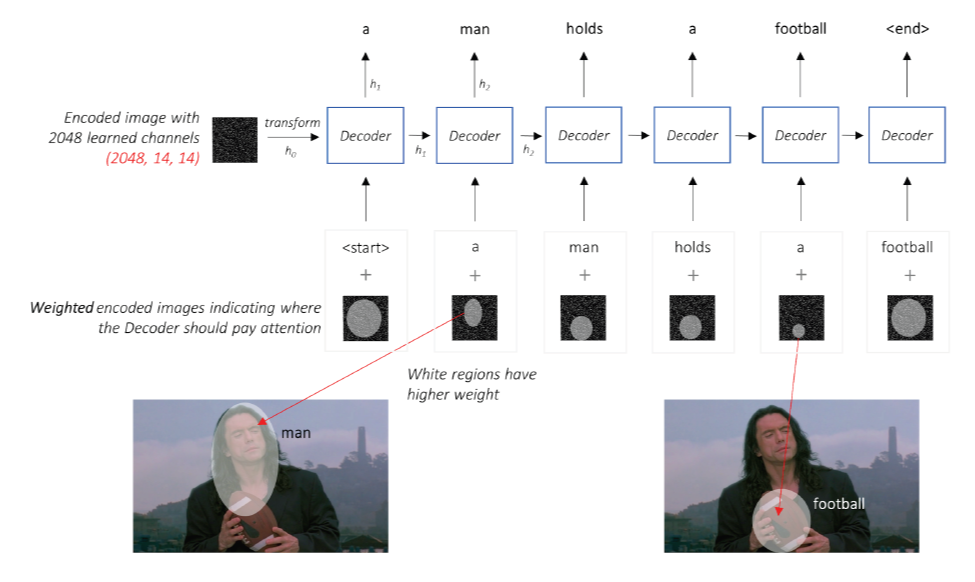
Architecture
- CNN part : input image를 Feature Tensor로 Encoding
- Pre-trianed 된 모델을 사용
- 모든 layer을 사용하는 것이 아닌 끝부분의 2개의 layer를 제거하고 사용한다.
why? 가장 마지막 layer를 통과하면 logit형태, 그 직전 layer는 Feature vector 형태
공간정보를 유지해줘야되기 때문에 Pooling layer와 Linear layer 제거 - encoder의 image size를 알고 있으면 편하다
- encoder의 output으로 (channel size,14,14) 나오게 되면 RNN에 feeding
class Encoder(nn.Module):
def __init__(self, img_size = 14):
super(Encoder, self).__init__()
self.img_size = img_size
resnet = models.resnet101(ptretrained = True)
module = list(resnet.children())[:-2]
self.resnet = nn.Sequential(*module)
- RNN part :
- Decoder부분에서는 순간순간 attention해줘야 될부분을 참고하면서 반복진행한다.
Beam search

조합이 많이 나오게 설정하고, 여지를 두어 가장 좋은 것만 뽑는것이 아니라 상위 n개를 보면서 step을 밟아 나간다
end가 나온 문장중에 가장 좋은 점수를 고르면 된다(?)
만약 첫 디코더에서 A가 가장 좋은 score로 나왔다면? A만을 참고하여 다음 디코더에 step하는 것이 아닌, 디코더에서 상위 n개의 score을 뽑아 낸다.
'AI 부스트캠프' 카테고리의 다른 글
| [YOLOv5] train + inference 자세하게 알아보자 (0) | 2021.10.09 |
|---|---|
| [Detectron2] code level review (0) | 2021.09.28 |
| [Week6 & Day4] Multi-Modal Learning (0) | 2021.09.17 |
| [Week6 & Day 3] Conditional Generative Model (0) | 2021.09.16 |
| [Week6 & Day1] CNN Visualization (0) | 2021.09.14 |