데이터의 표현방법이 모두 다른데, 이렇게 다른 차원들의 데이터를 어떻게 처리하지? ex) Audio = 1D / Image = 2D or 3D / Text = word에 대응되는 Embedding data
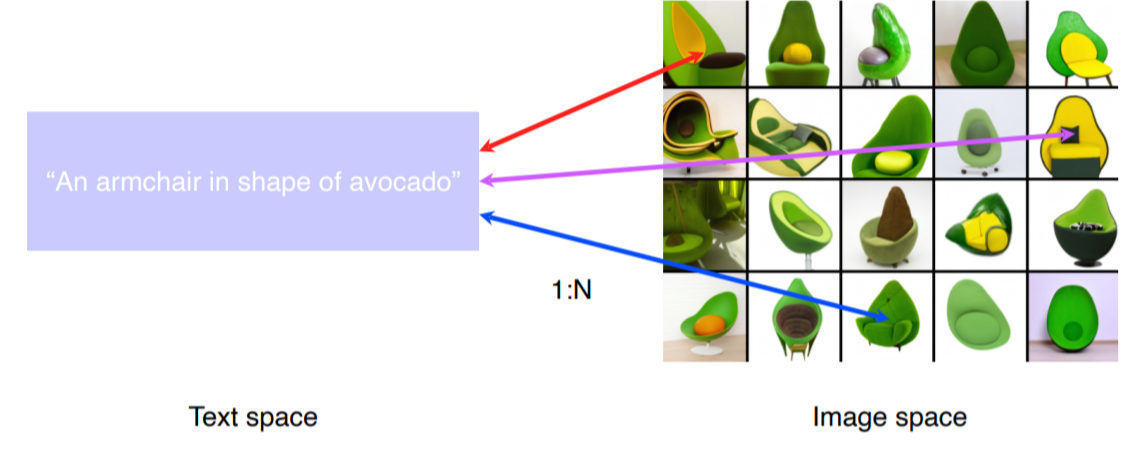
특징들 사이의 불균형 ex) 똑같은 shape을 가지고 있는 data는 여러개가 존재 / 즉 1 : N 매칭이 된다는 점
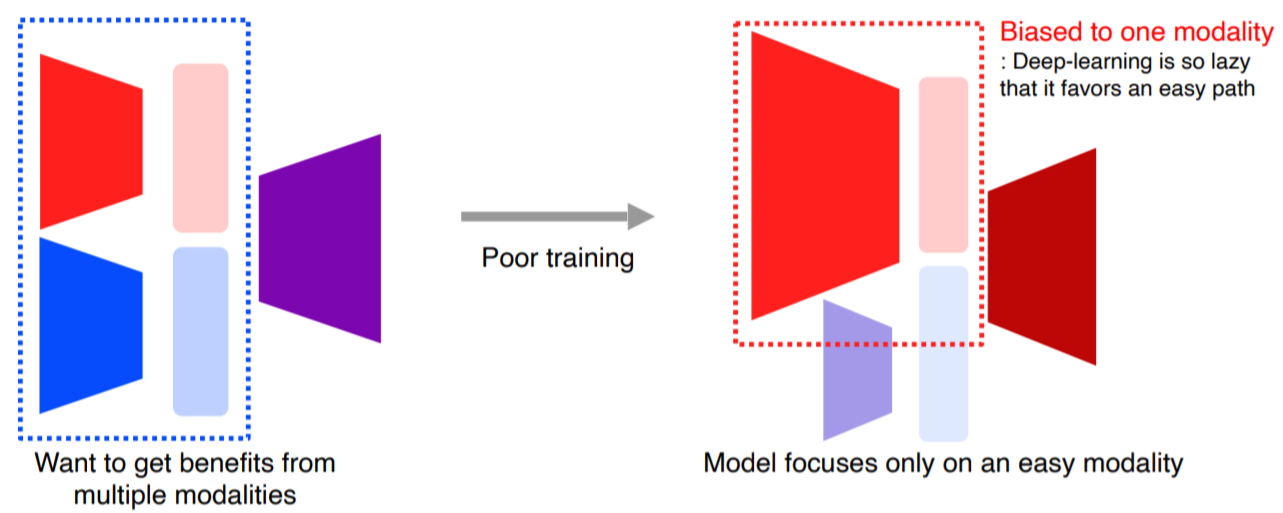
여러modality를 사용할때 fair하게 사용하면 더 좋게 학습되나? >>> 방해가 될때도 있다. 하나의 modality에 bias(편향)되는게 자주 발생한다. 또한 필요없는 모달리티는 안쓰게된다. 대부분은 visiual로 처리가 되는 경우가 많기에 다른 부분은 안쓰게되는 현상도잇음
그래도 불구하고 기존에 못하던 것을 해결할수도잇음(참조 + 상호작용 등을 이용한다)
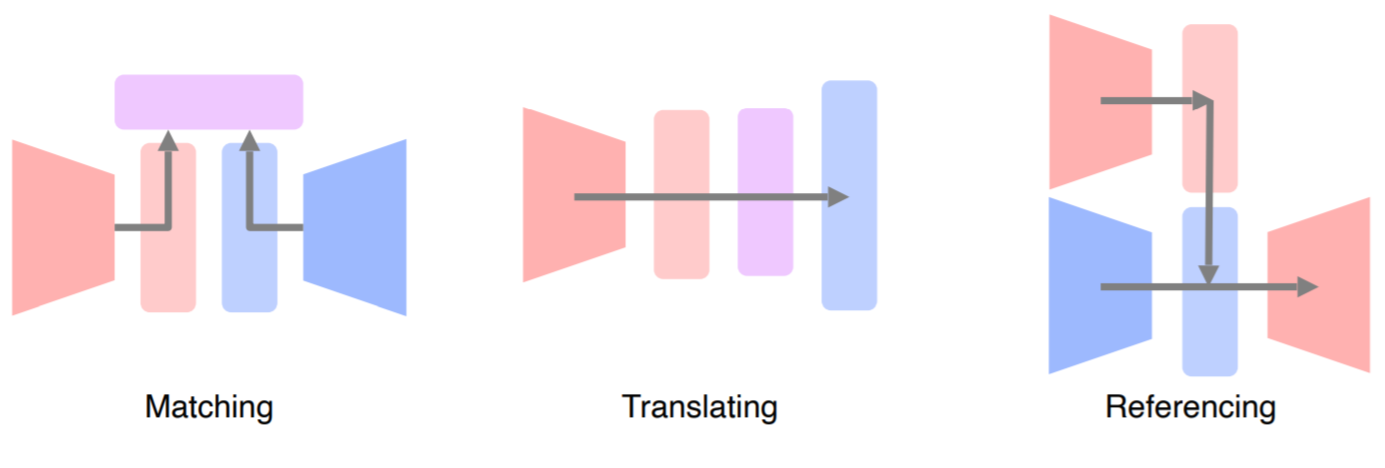
Matching : 여러개의 데이터 type을 공통된 공간으로 보내서 매칭
Translating : Modal을 다른 Modal로 translating 해주는 방법Referencing : 참조하는 방법
Visual data & Text
Text Embedding 이란?
문자는 머런돌리기에 어렵다 => dense vector로 표현해야된다. 예를 들어 남자와 여자의 관계와 왕과 여왕과의 관계를 보면 연관성을 갖는걸 볼수 있음
각 객체마다의 거리를 통해 두 단어 사이의 관계의 밀접도를 알 수 있다.
word2vec
W에서 하나의 행이 word를 의미 , input에서 들어갈때, 원핫벡터로 나타내어 지게 된다.
Hidden layer를 통해 학습한다.
단어와 단어사이의 관계를 학습하게 되는데, window size를 통해서 주위 단어수를 설정하고 그 size만큼 묶어서 학습을 하게된다.
Joint embedding
Matching
Image tagging
쌍방향 가능 : 이미지를주고 태깅 or 태그를 주고 이미징
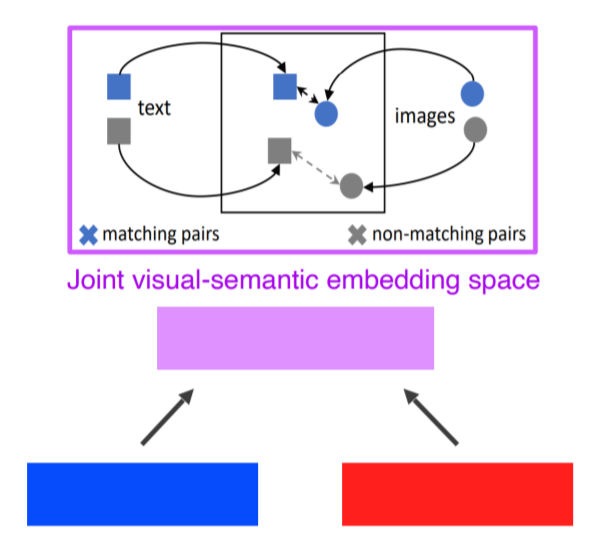
텍스트를 하나의 feature vector 형태로 표현 + 이미지도 하나의 feature vector 로 표현
보라색 상자 들어가기전에 fixed된 같은 차원의 feature vector으로 만들어준다.
텍스트와 이미지가 주어지면 같은 임베딩 공간에 두고 두개 사이의 인스턴스를 학습 : 서로 댕기거나 밀거나 하는 과정을 통해 학습한다 (거리) : Metrix learing
Translating : Cross modal translation
Image captioning
이미지에서 문장으로 변환하는 것, 이미지는 CNN 문장은 RNN
두개를 잘 합치는 것이 중요
Show and Tell
Encoder : input image가 들어오면 fixed 차원 벡터로 바꿔주기 위한 것 , CNN 이용
Decoder : LSTM modul s0는 이미지넷에서 나온 시작토큰 logp1(s1)은 한번 lstm돌린 결과, 이후 반복
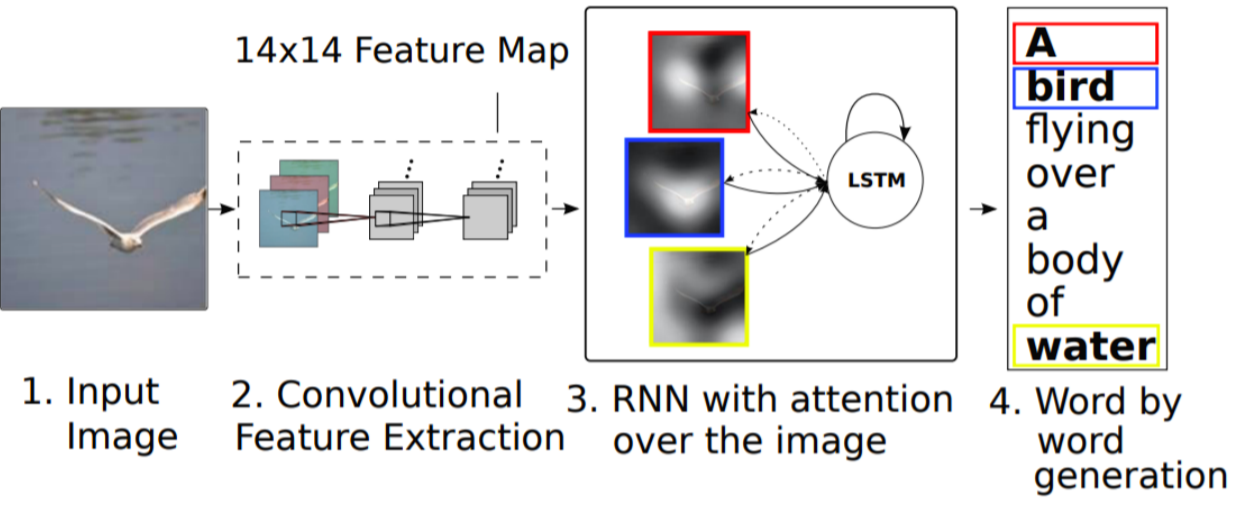
show attend tell
def. 내가 원하는 부분에 집중하여 출력, 단어에 매칭되는 이미지의 국소적인 부분을 집중적으로 학습한다
인풋이미지 cnn에 넣는다 > 14*14 feature map으로 출력 > rnn에 넣는다, 하나의 word를 생성할때 마다 feature map을 참조하면서 다음 단어를 생성한다
image가 주어지면 feature을 뽑고 lstm에 넣으면? >> 어떤 부분이 중요한지 weighted sum을 통해 z1(fixel 차원의 vector)을 만들고, y1을 conditional하게 참조하여 h1을 통해 어떤 단어로 시작할지 도출함 h1은 어디를 참조할지 soft attention map을 통해 알게 되고, 알게 된것을 feature에 넣어주고 위와 동일한 과정으로 z2를 만들게된다. y2는 이전에 출력했던 단어를 넣어주고 h2는 이것들을 통해 다음 단어를 예측한다. >>> 반복
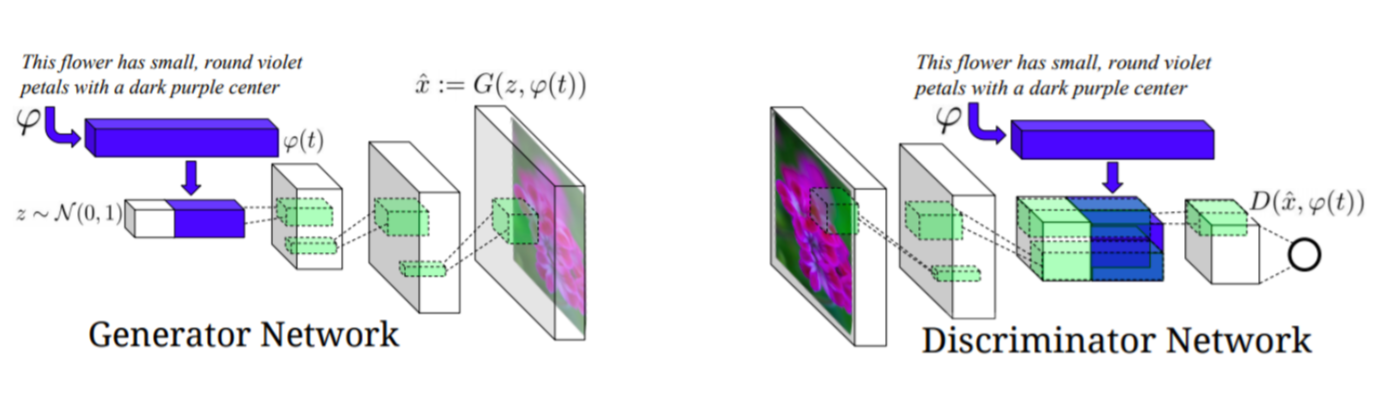
Text to Image : 1:N matching (즉, generative model이 필요)
Generator : 텍스트 전체를 고정된 벡터로 만들고 > 가우시안 랜덤코드를 해줘야됨(다양한 아웃풋이 나올수있도록) > 결과도출 (condition + input = C GAN)
Discriminator : 이미지가 생성된게 들어오면 feature을 뽑고 여기에 문장(얘는 Generator에서 썼던 문장, 즉 컨디서녈)을 합쳐서 true/false 판단